- Can open-source models like llama have comparables results to that of OpenAI?
- Is few-shot prompting a viable solution for enhancing the capabilities of llms?
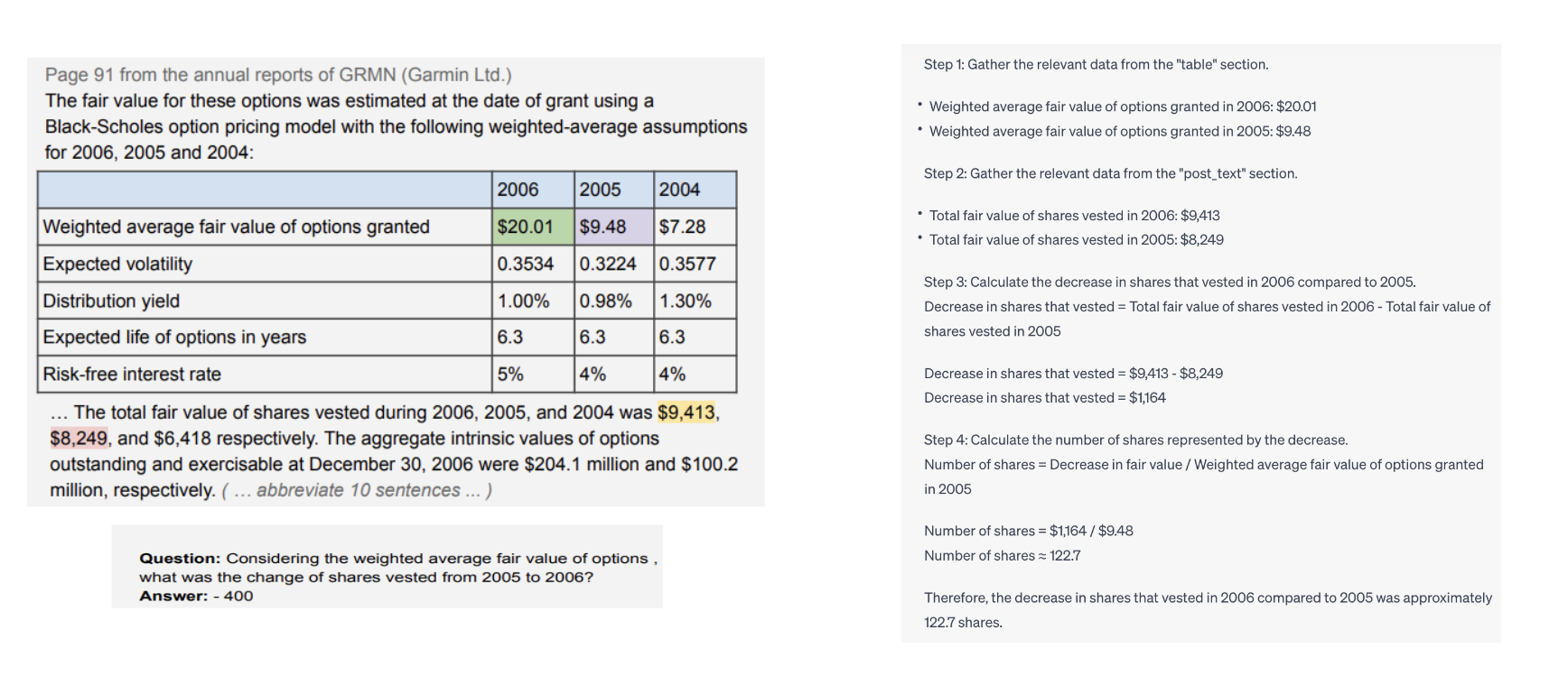
Problem Statement
Solution
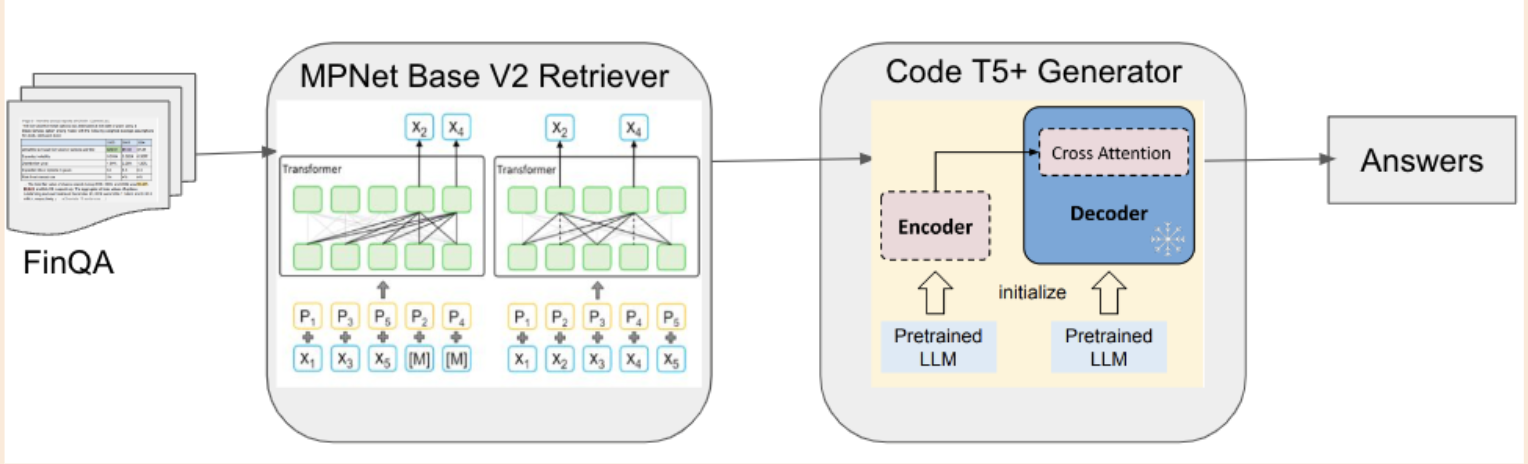
The dataset comprises 8281 QA pairs that involve tabular reasoning. The corpus along with the question is fed into the retriever as input. Each row of the table is then transformed into text to help the model treat it similar to any other textual content. The retriever then extracts the top n (in our case, 5) most relevant sentences for a given question. These retrieved details are subsequently input to the generator, which creates a program in Domain-Specific Language (DSL) to solve the problem. After evaluating the DSL, a mathematical entity is produced as the output. This architecture enables operations such as addition, subtraction, division, multiplication, maximum, minimum, and average.
Retriever: My initial experiments began with using llama 1. I started finetuning the smallest 7B param model and went on upto 30B param model. However, the pipeline didnt perform better than the FinQA baseline. Then I searched for a model that has been finetuned for retrieval and chose mpnet base. The uniqueness of this model is the MpNet embedding that solves the problem of both MLM and PermutedLM. It introduces dependency among predicted tokens, distinguishing it from the MLM used in BERT. On the other hand, To overcome position discrepancy, it incorporates auxiliary position information as input, allowing the model to perceive an entire sentence, in contrast to XLNet's use of PLM.
Here are the finetuned results for the retriever. Comparing to the Gold index results, two out of the three sentences retrieved by the model were sufficient in answering the question at hand. This gives us an overall accuracy of 89.73% for top 3 results and 93.5% for top 5 results
- Top 3: 89.73130022110768
- Top 5: 93.51251145985002
- Example:
the 2015 net revenue of amount ( in millions ) is $ 5829
net revenue utility following is an analysis of the change in net revenue comparing 2015 to 2014
the 2014 net revenue of amount ( in millions ) is $ 5735
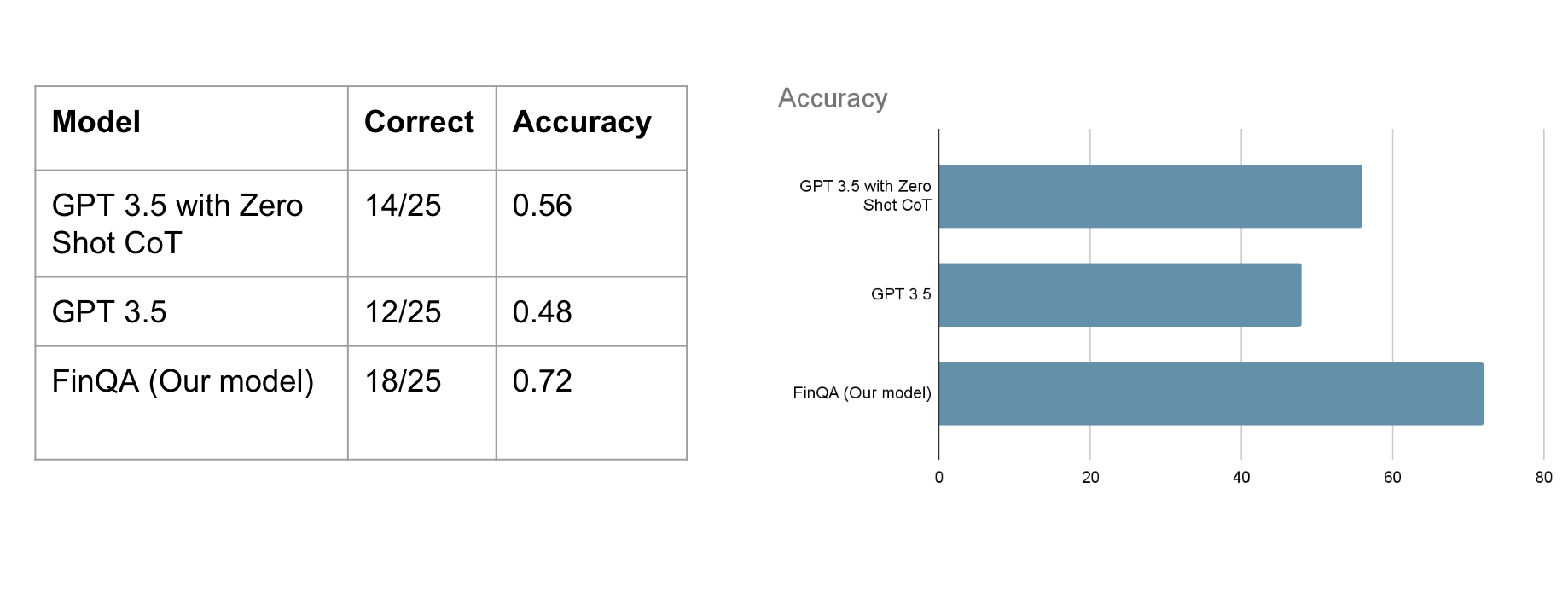
With respect to the results, we have two metrics - program accuracy and execution accuracy. Execution accuracy is more lenient and allows for different programs that might reach the same answer by chance or an alternative form of the program whereas program accuracy checks for whether the generated program is identical to the target. Having trained 2 models, one on the results of the retriever and another on the gold retrievals we see that in both cases we beat the general crowd performance. However, we are far from expert performance - a result of knowledge gained from being in the field for years, clearly warranting further research. An alternative approach we are currently testing is using CodeT5+ as a complete text-to-text generator which hopefully takes advantage of the model’s code generation and understanding capabilities.
- With retriever results
Program Accuracy (correct program): 58.77%
Execution Accuracy (correct answer): 61.61%
- With gold retrievals
Program Accuracy (correct program): 69.52%
Execution Accuracy (correct answer): 70.34%
Discussion and Future Work
Here are a few interesting observations that we've made.- Most of the successful operations involves computing the average, net change growth rate, balance, due, percentage change, net revenue
- Changing the word from portion to percentage gives us better results. This shows that the model is aware of commonly used words but does fail to recognise the synonyms of these words that are rarely used.
- Payment due vs payment due cash have different answers. Our experiments suggested that using cash confuses the model reducing its retrieval accuracy. This is mostly because in financial texts, the use of word cash is restrictive and the mode of payment usually doesnt have an impact
- Model still falls short when it comes to domain specific terms that are rarely explained even in financial corpus. These are words like debt commons, capital expenditure that are learnt by finance professionals with experience.
References
- Chen, Zhiyu, et al. "Finqa: A dataset of numerical reasoning over financial data." arXiv preprint arXiv:2109.00122 (2021)
- Song, Kaitao, et al. "Mpnet: Masked and permuted pre-training for language understanding." Advances in Neural Information Processing Systems 33 (2020): 16857-16867.
- Armineh Nourbakhsh, Cathy Jiao, Sameena Shah, and Carolyn Rosé (2022). Improving compositional generalization for multi-step quantitative reasoning in question answering. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 1916–1932, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- https://www.surgehq.ai/blog/surge-ai-and-meta-1m-human-rlhf-annotations-for-llama-2
- https://medium.com/@hari4om/word-embedding-d816f643140